2024. 4. 17. 23:12ㆍ카테고리 없음
목차
CPU의 기능
2.1 CPU의 기본 구조
2.2 명령어 실행
2.3 명령어 파이프라이닝
2.4 명령어 세트
< CPU의 기능 >
- 명령어 인출(Instruction Fetch): 기억장치로부터 명령어를 읽어온다.
- 명령어 해독(Instruction Decode): 수행해야 할 동작을 결정하기 위하여 명령어를 해독한다
~> 위의 두 기능은 모든 명령어들에 대하여 공통적으로 수행
- 데이터 인출(Data Fetch): 명령어 실행을 위하여 데이터가 필요한 경우에는 기억장치 혹은 I/O 장치로부터 그 데이터를 읽어온다.
- 데이터 처리(Data Process): 데이터에 대한 산술적 혹은 논리적 연산을 수행
- 데이터 저장(Data Store): 수행한 결과를 저장
~> 명령어에 따라 필요한 경우에만 수행
< 2.1 CPU의 기본 구조 >
1. CPU의 기본 구조
> 산술논리연산장치(ALU, Arithmetic and Logical Unit), 레지스터 세트(Register Set), 제어 유니트(Control Unit)
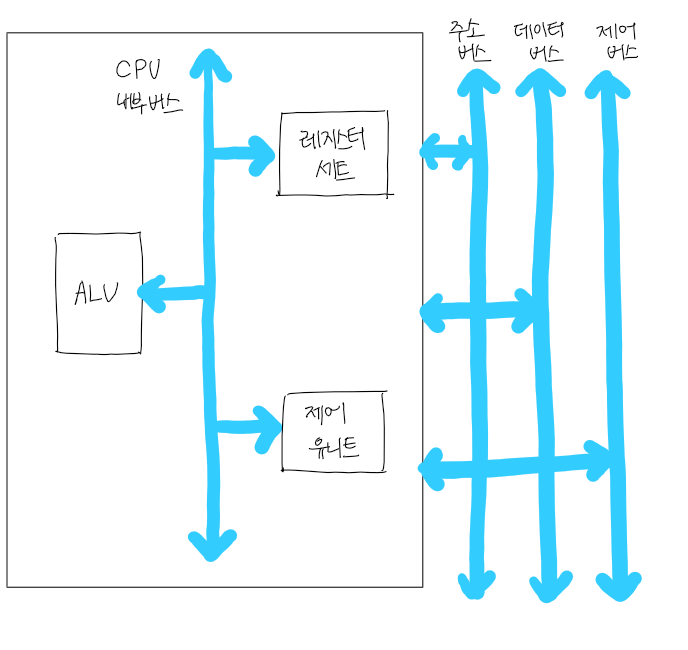
2. CPU의 내부 구성요소
- ALU
> 각종 산술 연산들과 논리 연산들을 수행하는 회로들로 이루어진 하드웨어 모듈
> 산술 연산: +, -, ×, ÷
> 논리 연산: AND, OR, NOT, XOR, TRUE(1), FALSE(0) 등
- 레지스터(register)
> 액세스 속도가 가장 빠른 기억장치
> 고가, 부피 크다
> CPU 내부에 포함할 수 있는 레지스터들의 수가 제한됨
(특수목적용 레지스터들(다음 수행 명령어를 가지는 PC 등) & 적은 수의 일반목적용 레지스터들)
- 제어 유니트
> 프로그램 코드(명령어)를 해석하고, 그것을 실행하기 위한 제어 신호들을 순차적으로 발생하는 하드웨어 모듈
- CPU 내부 버스(CPU internal bus)
> ALU와 레지스터들 간의 데이터 이동을 위한 데이터 선들과 제어 유니트로부터 발생되는 제어 신호 선들로 구성된 내부 버스
> 외부의 시스템 버스들과는 직접 연결되지 않으며, 반드시 버퍼 레지스터들 혹은 시스템 버스 인터페이스 회로를 통하여 시스템 버스와 접속
< 2.2 명령어 실행 >
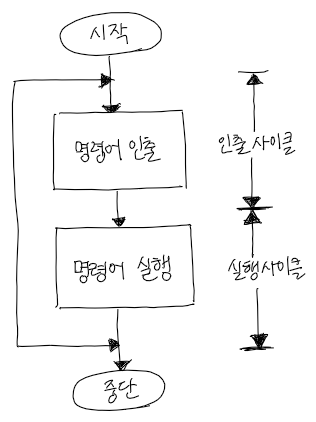
1. 기본 명령어 사이클
- 명령어 사이클(instruction cycle)
: CPU가 한 개의 명령을 실행하는 데 필요한 전체 처리 과정으로서, CPU가 프로그램 실행을 시작한 순간부터 전원을 끄거나 회복 불가능한 오류가 발생하여 중단될 때까지 반복
- 두 개의 부사이클(subcycle)들로 분리
> 인출 사이클(fetch cycle): CPU가 기억장치로부터 명령어를 읽어오는 단계
> 실행 사이클(execution cycle): 명령어를 실행하는 단계
2. 명령어 실행에 필요한 CPU 내부 레지스터들
1) 프로그램 카운터(PC, Program Counter)
- 다음에 인출할 명령어 주소를 가지고 있는 레지스터
- 각 명령어가 인출된 후에는 자동적으로 일정 크기(한 명령어 길이)만큼 증가
- 분기(branch) 명령어가 실행되는 경우에는 목적지 주소로 갱신
2) 누산기(AC, Accumulator)
- 데이터를 일시적으로 저장하는 레지스터.
- 레지스터의 길이는 CPU가 한 번에 처리할 수 있는 데이터 비트 수(단어 길이)와 동일
3) 명령어 레지스터(IR, Instruction Register)
- 가장 최근에 인출된 명령어 코드가 저장되어 있는 레지스터
4) 기억장치 주소 레지스터(MAR, Memory Address Register)
- PC에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 주소 레지스터
5) 기억장치 버퍼 레지스터(MBR, Memory Buffer Register)
- 기억장치에 쓰여질 데이터 혹은 기억장치로부터 읽힌 데이터를 일시적으로 저장하는 버퍼 레지스터

< 2.2.1 인출 사이클 >
- 인출 사이클의 마이크로 연산(micro-operation)
| t0: MAR <- PC t1: MBR <- M[MAR], PC <- PC+1 t2: IR <- MBR 단, t0, t1 및 t2는 CPU 클록(clock) 주기 |
[ 첫 번째 주기 ] 현재의 PC 내용을 CPU 내부 버스를 통하여 MAR로 전송
[ 두 번째 주기 ] 그 주소가 지정하는 기억장치 위치로부터 읽힌 명령어가 데이터 버스를 통하여 MBR로 적재되며, PC의 내용에 1을 더한다
[ 세 번째 주기 ] MBR에 있는 명령어 코드가 명령어 레지스터인 IR로 이동
[ 예 ] CPU 클록 주파수 = 1GHz(클록 주기 = 1ns)
-> 인출 사이클: 1ns x 3 = 3ns 소요
- 인출 사이클의 주소 및 명령어 흐름도

< 2.2.2 실행 사이클 >
- CPU는 실행 사이클 동안에 명령어 코드를 해독(decode)하고, 그 결과에 따라 필요한 연산들을 수행
- CPU가 수행하는 연산들의 종류
> 데이터 이동: CPU가 기억장치 간 혹은 I/O장치 간에 데이터를 이동
> 데이터 처리: 데이터에 대하여 산술 혹은 논리 연산을 수행
> 데이터 저장: 연산 결과 데이터 혹은 입력장치로부터 읽어 들인 데이터를 기억장치에 저장
> 프로그램 제어: 프로그램의 실행 순서를 결정
- 실행 사이클에서 수행되는 마이크로-연산들은 명령어의 연산 코드(op code)에 따라 결정됨
1. 기본적인 명령어 형식의 구성
- 연산 코드(operation code)
: CPU가 수행할 연산을 지정
- 오퍼랜드(operand)
: 명령어 실행에 필요한 데이터가 저장된 주소(addr)

2. [ 사례1 ] LOAD addr 명령어
- 기억장치에 저장되어 있는 데이터를 CPU 내부 레지스터인 AC로 이동하는 명령어
| t0: MAR <- IR(addr) t1: MBR <- M[MAR] t2: AC <- MBR |
[ 첫번째 주기 ] 명령어 레지스터 IR에 있는 명령어의 주소 부분을 MAR로 전송
[ 두번째 주기 ] 그 주소가 지정한 기억장소로부터 데이터를 인출하여 MBR로 전송
[ 세번째 주기 ] 그 데이터를 AC에 적재

3. [ 사례2 ] STA addr 명령어
- AC 레지스터의 내용을 기억장치에 저장하는 명령어
| t0: MAR <- IR(addr) t1: MBR <- AC t2: M[MAR] <- MBR |
[ 첫번째 주기 ] 데이터를 저장할 기억장치의 주소를 MAR로 전송
[ 두번째 주기 ] 저장할 데이터를 버퍼 레지스터인 MBR로 이동
[ 세번째 주기 ] MBR의 내용을 MAR이 지정하는 기억장소에 저장

4. [ 사례3 ] ADD addr 명령어
- 기억장치에 저장된 데이터를 AC의 내용과 더하고 그 결과는 다시 AC에 저장하는 명령어
| t0: MAR <- IR(addr) t1: MBR <- M[MAR] t2: AC <- AC + MBR |
[ 첫번째 주기 ] 데이터를 저장할 기억장치의 주소를 MAR로 전송
[ 두번째 주기 ] 저장할 데이터를 버퍼 레지스터인 MBR로 이동
[ 세번째 주기 ] 그 데이터와 AC의 내용을 더하고 결과값을 다시 AC에 저장

5. [ 사례4 ] JUMP addr 명령어
- 오퍼랜드(addr)가 가리키는 위치의 명령어로 실행 순서를 변경하는 분기(branch) 명령어
| t0: PC <- IR(addr) |
> 명령어의 오퍼랜드(분기할 목적지 주소)를 PC에 저장
> 다음 명령어 인출 사이클에서 그 주소의 명령어가 인출되므로, 분기가 발생
6. 어셈블리 프로그램 실행과정의 예
- 연산 코드에 임의의 정수 배정
{ LOAD: 1 / STA: 2 / ADD: 5 / JUMP: 8 }
- 어셈블리 프로그램의 예
| 주소 | 명령어 | 기계코드 |
| 100 | LOAD 250 | 1250 |
| 101 | ADD 251 | 5251 |
| 102 | STA 251 | 2251 |
| 103 | JUMP 170 | 8170 |
> LOAD 명령어

~> 100번지의 첫 번째 명령어 코드가(1250) 인출되어 IR에 저장
~> LOAD 250 = 1250(IR): 250번지의 데이터를 AC로 이동
~> PC = PC + 1 = 101
> ADD 명령어
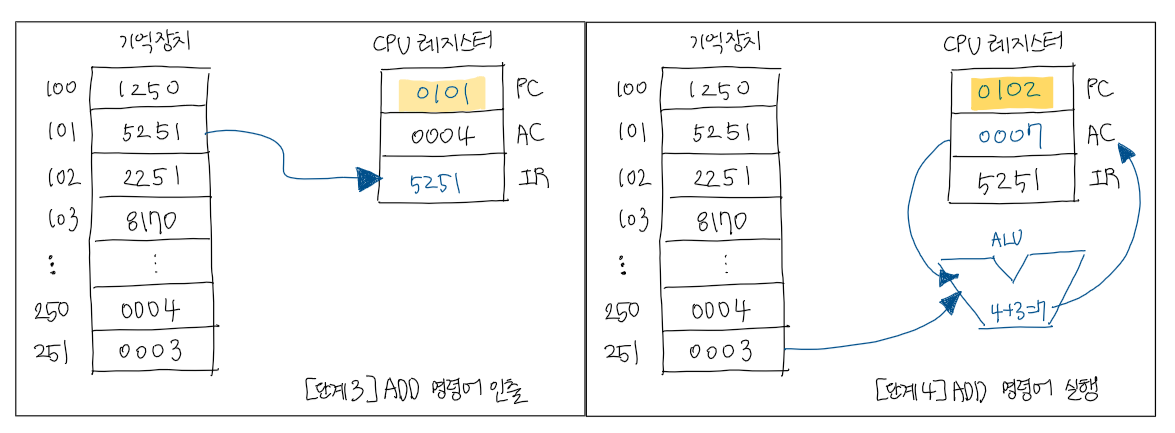
~> 두 번째 명령어 코드가(5251) 101번지로부터 인출되어 IR에 저장
~> ADD 251 = 5251(IR) = AC의 내용과 251번지의 내용을 더하고, 결과를 AC에 저장
~> PC = PC + 1 = 102
> STA 명령어

~> 세 번째 명령어 코드가(2251) 102번지로부터 인출되어 IR에 저장
~> STA 251 = 2251(IR) = AC의 내용을 251번지에 저장
~> PC = PC + 1 = 103
> JUMP 명령어

~> 네 번째 명령어 코드가(8170) 103번지로부터 인출되어 IR에 저장
~> JUMP 170 = 8170(IR) = 분기될 목적지 주소, 즉 IR의 하위 부분(170)이 PC로 적재
(~> 다음 명령어 인출 사이클에서는 170번지의 명령어 인출)
< 2.2.3 인터럽트 사이클(interrupt cycle) >
- 인터럽트: 프로그램 실행 중에 CPU의 현재 처리 순서를 중단시키고 다른 동작을 수행하도록 요구하는 시스템 동작
- 외부로부터 인터럽트 요구가 들어오면?
> CPU는 원래의 프로그램 수행을 중단하고,
> 요구된 인터럽트를 위한 서비스 프로그램을 먼저 수행
- 인처럽트 서비스 루틴(ISR, interrupt service routine)
> 인터럽트를 처리하기 위하여 수행되는 프로그램 루틴
- 인터럽트에 의한 제어의 이동

1. 인터럽트 처리 과정
- 인터럽트가 들어왔을 때 CPU는
> 어떤 장치가 인터럽트를 요구했는지 확인하고, 해당 ISR을 호출
> 서비스가 종료된 다음에는 중단되었던 원래 프로그램의 수행 계속
- CPU 인터럽트 처리의 세부 동작(인터럽트 사이클 동안 수행)
1) 현재의 명령어 실행을 끝낸 즉시, 다음에 실행할 명령어의 주소(PC의 내용)을 스택(stack)에 저장
~> 일반적으로 스택은 주기억장치의 특정 부분
2) ISR을 호출하기 위하여 그 루틴의 시작 주소를 PC에 적재. 이때 시작 주소는 인터럽트를 요구한 장치로부터 전송되거나 미리 정해진 값으로 결정.

2. 인터럽트 사이클의 마이크로 연산
| t0: MBR <- PC t1: MAR <- SP, PC <- ISR의 시작 주소 t2: M[MAR] <- MBR |
(*단, 스택포인터(SP, Stack Pointer)는 스택의 최상위 주소(TOS: top of stack)를 저장하고 있는 레지스터이며, 저장 후에는 1 감소)
[ 첫번째 주기 ] PC의 내용을 MBR로 전송
[ 두번째 주기 ] SP의 내용을 MAR로 전송하고, PC의 내용은 인터럽트 서비스 루틴의 시작 주소로 변경
[ 세번째 주기 ] MBR에 저장되어 있던 원래 PC의 내용을 스택에 저장
3. 인터럽트 사이클의 마이크로 연산 [예]
- 아래 프로그램의 첫 번째 명령어인 LOAD 250 명령어가 실행되는 동안 인터럽트가 들어왔으며, 현재 SP = 999이고, 인터럽트 서비스 루틴의 시작 주소는 650번지라고 가정
| 100 | LOAD | 250 |
| 101 | ADD | 251 |
| 102 | STA | 251 |
| 103 | JUMP | 170 |
- Example






4. 인터럽트 요구가 들어온 경우의 상태 변화

5. 다중 인터럽트(multiple interrupt)
- 인터럽트 서비스 루틴을 수행하는 동안에 다른 인터럽트 발생
- 다중 인터럽트 처리 방법
1) CPU가 인터럽트 서비스 루틴을 처리하고 있는 도중에는 새로운 인터럽트 요구가 들어오더라도 인터럽트 사이클을 수행하지 않는 방법
> 인터럽트 플래그(interrupt flag) <- 0: 인터럽트 불가능(interrupt disabled) 상태
> 시스템 운영상 중요한 프로그램이나 도중에 중단할 수 없는 데이터 입출력 동작 등을 위한 인터럽트를 처리하는데 사용
2) 인터럽트의 우선순위를 정하고, 우선순위가 낮은 인터럽트가 처리되고 있는 동안에 우선순위가 더 높은 인터럽트가 들어온다면, 현재의 인터럽트 서비스 루틴의 수행을 중단하고 새로운 인터럽트를 먼저 처리
- 장치 X를 위한 ISR X를 처리하는 도중에 우선순위가 더 높은 장치 Y로부터 인터럽트 요구가 들어와서 먼저 처리하는 경우에 대한 제어의 흐름

< 2.2.4 간접 사이클(indirect cycle) >
- 명령어에 포함되어 있는 주소를 이용하여, 그 명령어 실행에 필요한 데이터의 주소를 인출하는 사이클
~> 간접 주소지정 방식(indirect addressing mode)에서 사용
- 인출 사이클과 실행 사이클 사이에 위치
- 간접 사이클에서 수행될 마이크로-연산
| t0: MAR <- IR(addr) t1: MBR <- M[MAR] t2: IR(addr) <- MBR |
> 인출된 명령어의 주소 필드 내용을 이용하여 기억장치로부터 데이터의 실제 주소를 인출하여 IR의 주소 필드에 저장
< 2.3 명령어 파이프라이닝 >은 다음 장에서 이어집니다.